【深入解讀】機器學習預測高溫合金蠕變斷裂壽命
2020-07-26 來源:Goal Science
從本期開始,我們將嘗試不定期選取部分國際權威期刊近期發表的金屬領域相關論文,在介紹研究成果的同時,也提供一些學術觀點共各位讀者批判和討論,希望能幫助大家更好地了解學術前沿的熱點難點,起到拋磚引玉的作用。非常歡迎各位讀者在評論區分享自己的觀點,或對欄目提出寶貴意見。
論文速讀
蠕變是合金在高溫服役時最重要的性能參數之一。然而,蠕變性能的實驗測量卻是十分耗時且昂貴的,一個實驗樣本點的獲取往往就需要幾千甚至幾萬小時,消耗的科研經費以萬計。得益于近年來數據科學的快速發展,越來越多的研究者開始嘗試通過機器學習的方法對合金的蠕變性能進行預測。
近日,來自上海大學、清華大學、鋼鐵研究總院等多個單位的合作團隊在Acta Materialia發表了其在利用機器學習方法預測鎳基單晶高溫合金蠕變性能方面取得的最新進展。模型訓練集共涵蓋鎳基單晶高溫合金的266組數據樣本,除了成分和熱處理工藝等22組基礎特征以外,研究團隊還引入了層錯能、擴散系數、剪切模量、晶格常數、γ'相分數等5組額外的物理特征作為模型輸入。這些物理特征可以通過Thermo-calc結合物理唯象模型獲取。與其他文獻中已發表的用于預測材料蠕變性能的機器學習模型不同的是,該模型在運行的初始階段引入了一步無監督聚類算法,將266組數據分為8個子類。使用支持向量機、隨機森林、高斯回歸等5種算法對每個子類中的數據進行單獨訓練,選擇其中效果最好的算法作為該子類的算法,最終使得模型對整體數據的預測性能大幅提高。
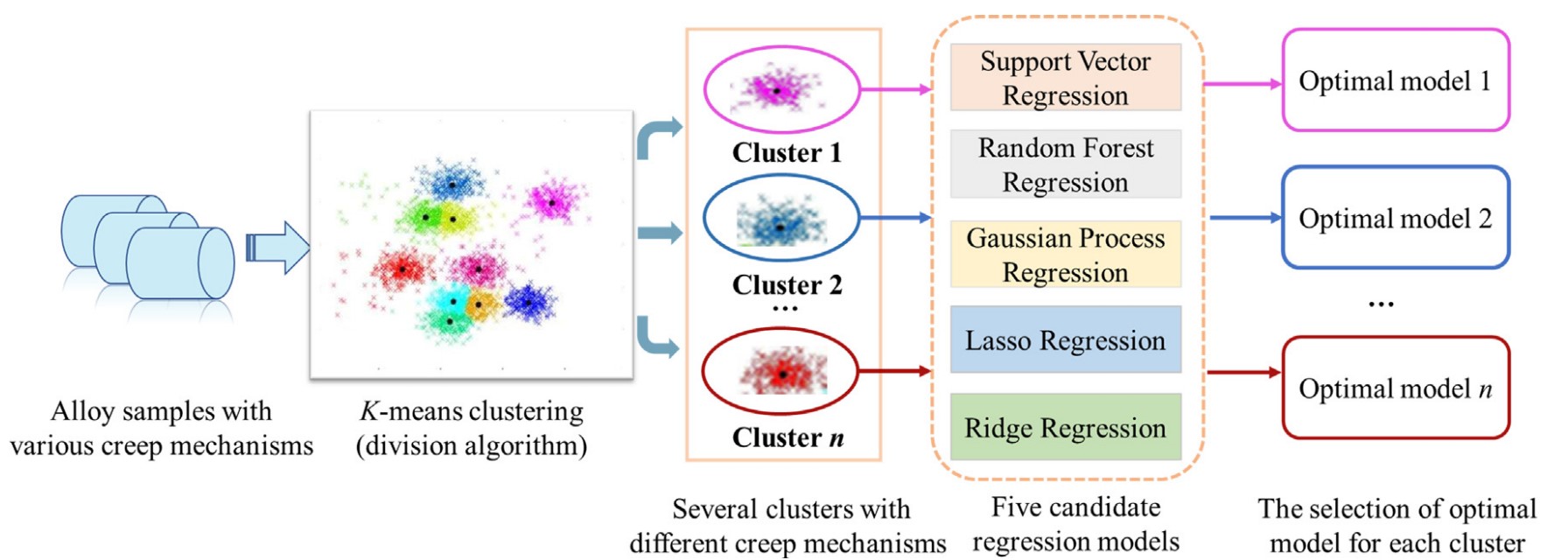
圖1 機器學習模型流程圖
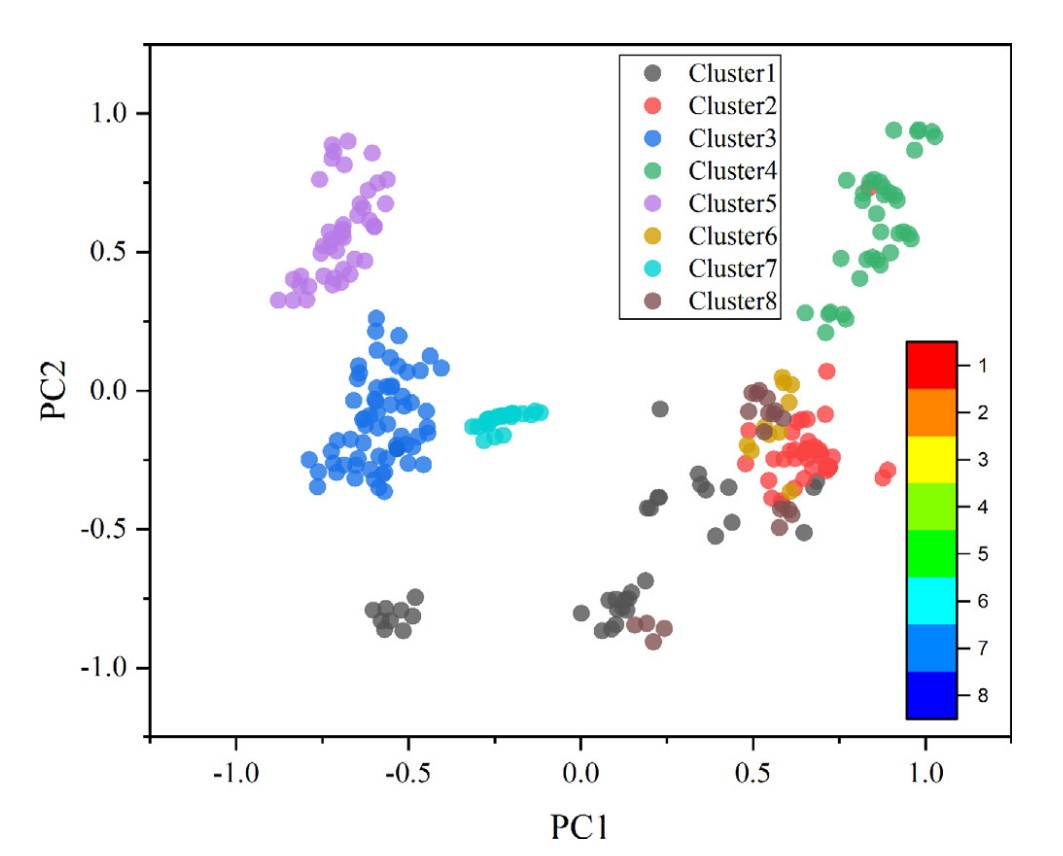
圖2 樣本聚類后在二維平面的投影
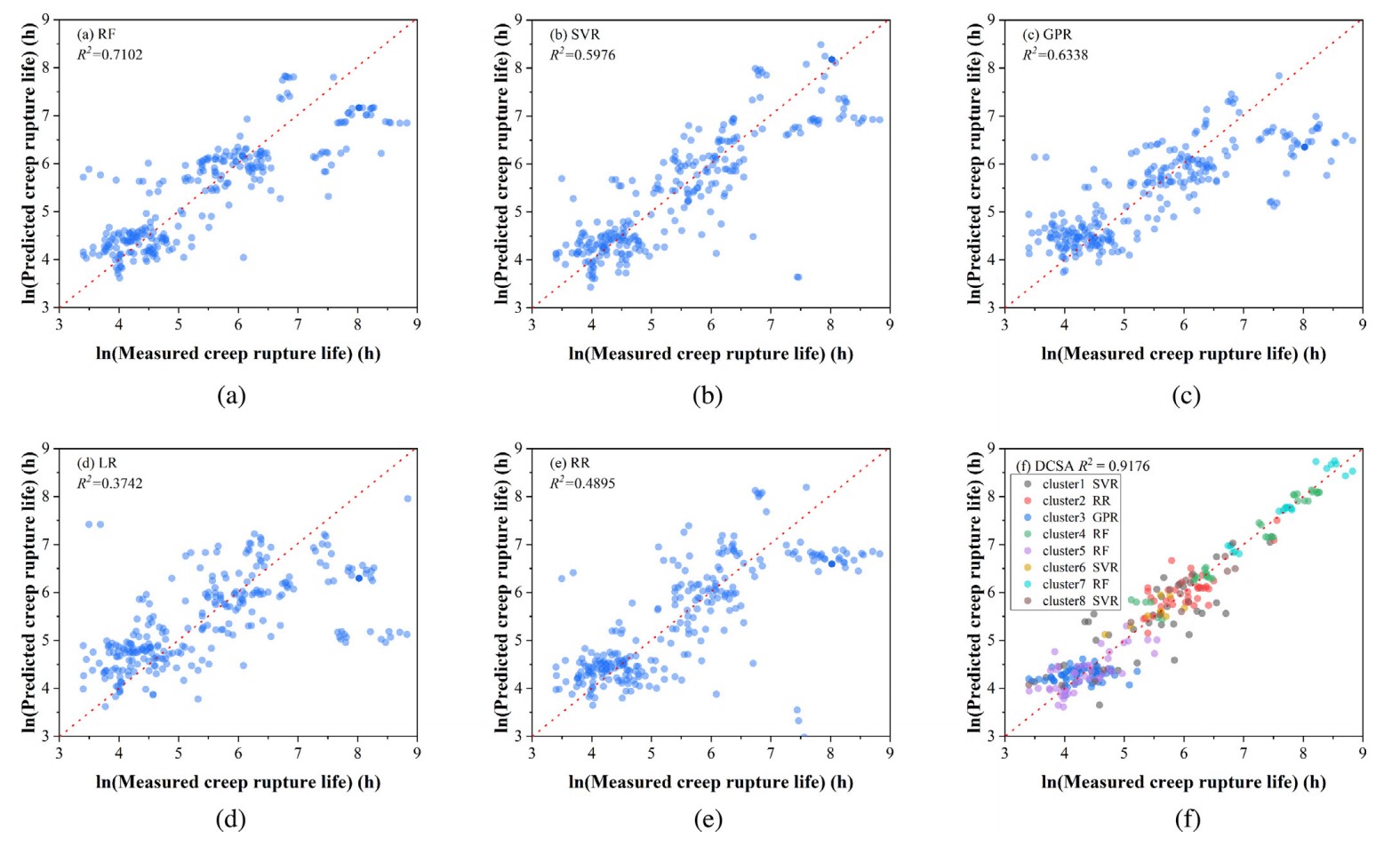
圖3 “分治”模型和其他5種模型的性能對比
觀點評述
近年來,在國際權威期刊上越來越多地開始出現機器學習在材料領域應用的相關文章。這一方面是由于人工智能的高熱度,另一方面也意味著在計算機科學與材料科學的交叉領域,還有大量值得探索的學術荒地。而其中,利用機器學習預測蠕變性能又是特別有意義的,因為蠕變實驗所需花費的時間和財力成本通常遠非其他實驗可比。長久以來,機器學習在合金蠕變性能預測方面的挑戰主要集中在以下幾個方面:
(1)蠕變性能的已有數據相對較少,因此這是一個稀疏數據集上的訓練問題,模型必須一方面避免對已有數據的過擬合,同時盡可能地提高模型的泛化能力。
(2)機器學習的過程往往是一個黑箱,如何將模型與實際的物理過程建立聯系,從而基于模型預測結果啟發或加深對實際過程物理圖像的理解,這是材料科學家相比于傳統的計算機科學家更關心的問題。
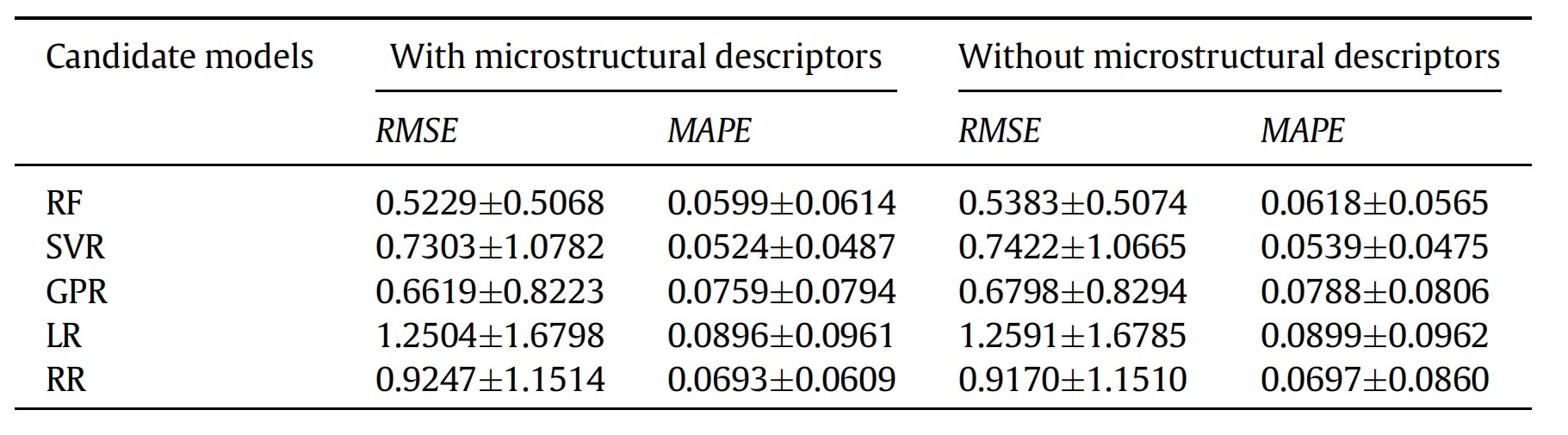
最近在Acta Materialia上發表的這項研究,是一項十分具有啟發性的工作,首先最顯而易見的亮點自然是模型成功地大幅提高了預測性能。此外,針對我們之前提到的兩點挑戰,研究團隊也提供了一些有益的嘗試。比如說,引入層錯能等具有物理意義的特征作為模型的輸入,就是可能的,也是目前較為常見的,利用機器學習揭示影響材料蠕變性能的物理參數的手段之一。這種發法并非本文的研究團隊首創,此前已有團隊將Thermo-calc熱力學軟件中的計算結果直接作為機器學習模型的輸入。但值得一提的是,本文的研究團隊在此基礎之上更進了一步,將熱力學軟件計算結果(如原子占位分數等)首先帶入了感興趣的,同時也可能是對蠕變性能有重要影響的物理量的有關公式,隨后再將計算結果帶入模型。因此,從某種意義上來說,這一模型更多地融入了前人對材料物理機制的認識。但是很遺憾地,結果并不理想。在此,我們引用文章中的一張表格(見表1)。該表格中的數據結果表明,只使用22組基本特征(主要包括成分和工藝參數)和額外引入5組物理特征作為輸入后,模型的性能并未出現顯著差異。這與19年Acta上表發的另一篇利用機器學習預測合金蠕變性能的文章Modern data analytics approach to predict creep of high-temperature alloys 中的結論一致。因此,在通過向機器學習模型中引入具有物理意義的特征作為輸入,以此揭示材料蠕變機理這條道路上,研究者可能還需要更多的思考和嘗試。至少就目前來說,我們甚至不知道,這種方法是否真的有效。
表1 模型輸入特征的選擇對模型性能的影響

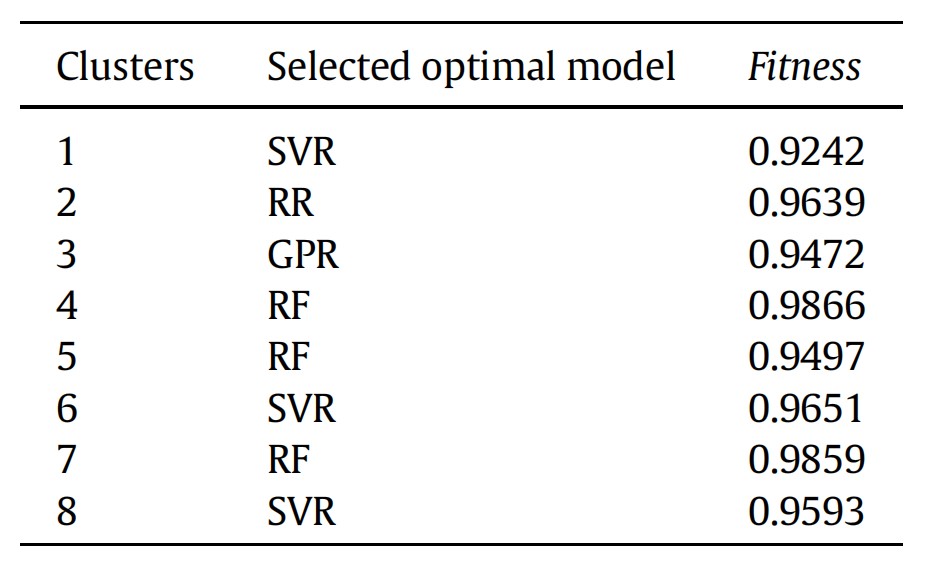
另外,在本研究中,作者首先對266組數據點進行了無監督聚類,隨后每個子類都通過訓練,選擇了RF, SVR, GPR, LR和RR這5種算法中的最佳算法,因此模型在整體數據集上的性能提高是可以預見的。事實上,這種所謂的“分而治之”(divide-and-conquer)機器學習模型最大優勢之一,是可以通過少量的訓練,快速地在子類和算法之間建立聯系,從而在面對大數據集時,越過中間的算法選擇環節,節約大量算力。因此從數據科學的角度來說,模型的優勢在面對蠕變性能預測這樣的稀疏問題上尚未得到充分發揮。但對于材料科學家而言重要的是,研究團隊發現無監督聚類的結果在一定程度上反應了鎳基單晶高溫合金的代際特征,且不同子類對應不同的算法選擇(見表2)。這反映聚類算法這種對相似性的度量具有一定的物理意義。不同的算法對應也可能是各個子類鎳基單晶高溫合金蠕變機制不同的一種暗示,雖然就目前而言證據還遠遠不足,但這種挖掘機器學習模型與材料物理機制嘗試在現階段已經是非常有意義的了。
表2 不同數據子類對應的算法
歡迎留言,材料科學的進步,需要您的發聲!
原文鏈接: